Real-Time Analytics with Azure Databricks: A Case Study
- Cloud
- November 18, 2024
-
Real-Time Analytics with Azure Databricks: A Case Study
Introduction
Azure Databricks is a powerful platform that combines the best of Apache Spark and Azure to provide a unified analytics workspace for big data processing, machine learning, and data engineering. In this blog, we’ll explore a real-world case study of how a financial services client used Azure Databricks to implement real-time analytics for fraud detection.
Client Overview and Challenges
Client Overview
The client is a financial services company specializing in credit card processing, handling millions of transactions daily. The company wanted to strengthen its fraud detection system to improve customer trust and reduce financial losses.
Challenges
- High Data Volume: Over 10 million transactions were processed daily, creating a large volume of data to analyze.
- Latency in Detection: Traditional batch processing delayed fraud detection, increasing risks.
- Scattered Data Sources: Transaction data came from various sources (databases, APIs, and logs).
- Need for Machine Learning: Identifying fraudulent patterns required a robust machine-learning pipeline.
- Scalability Issues: Existing infrastructure struggled to scale with the increasing data volume.
The client sought a real-time analytics solution that could handle large-scale data ingestion, processing, and machine-learning workflows.
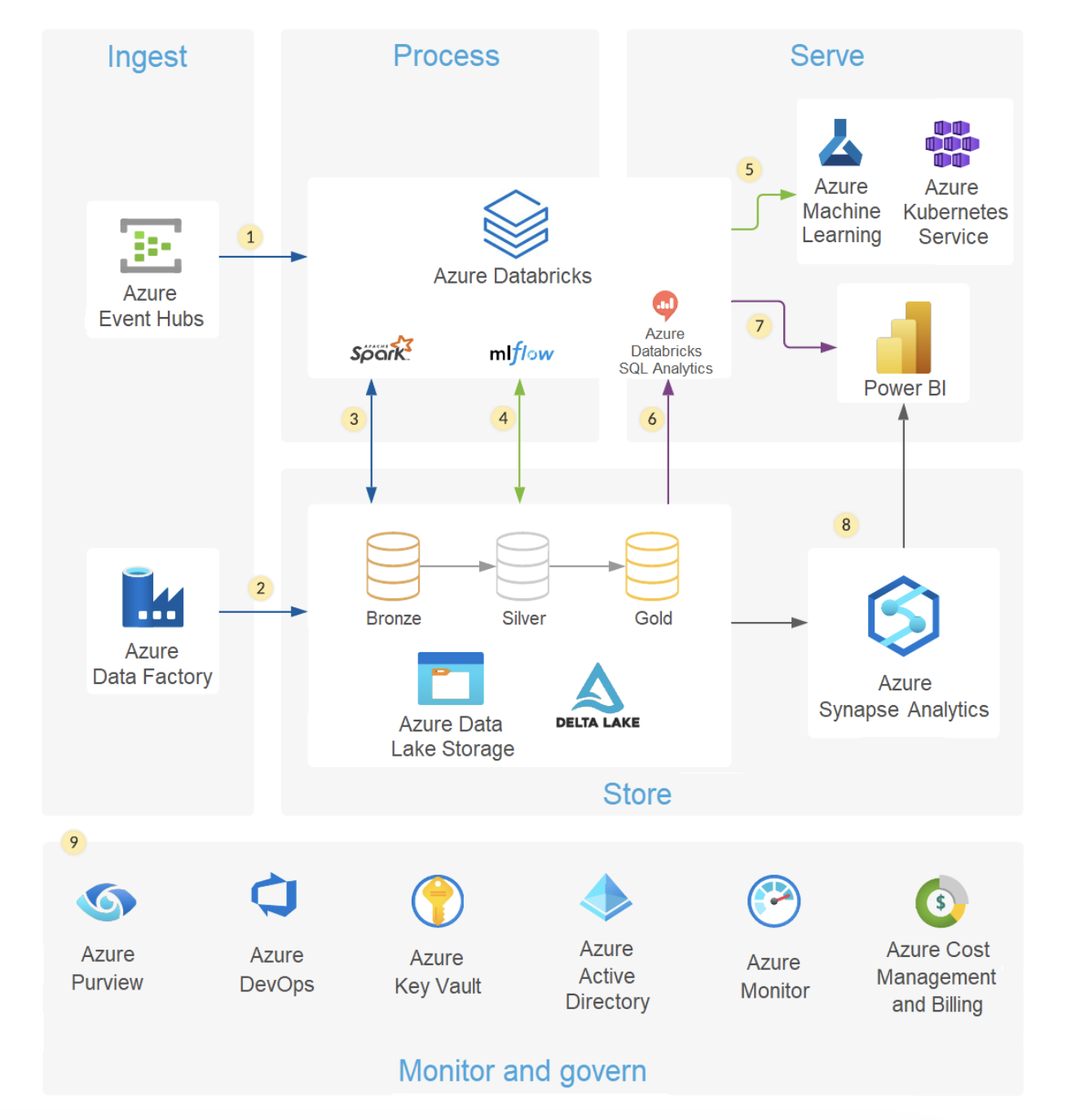
Solution: Implementing Azure Databricks for Real-Time Fraud Detection
We designed a real-time fraud detection system using Azure Databricks, leveraging its capabilities for distributed data processing, machine learning, and seamless Azure integration.
Key Components of the Solution
1. Real-Time Data Ingestion with Event Hubs and Azure Databricks
- Problem: Transaction data needed to be ingested and processed in real-time.
- Solution:
- Azure Event Hubs was used to ingest transaction data streams from various sources.
- Azure Databricks notebooks were configured to consume the data in real-time using Spark Structured Streaming.
- Data was cleaned, transformed, and enriched within Databricks before being stored in a Delta Lake.
Outcome:
- Real-time ingestion ensured transaction data was immediately available for analysis.
- Spark’s scalability handled millions of events seamlessly.
2. Machine Learning Pipeline for Fraud Detection
- Problem: Detecting fraudulent patterns required advanced machine learning capabilities.
- Solution:
- A Databricks notebook was used to develop a machine-learning model using MLlib.
- Historical transaction data was used to train a Random Forest model to identify fraudulent transactions.
- The trained model was deployed as a real-time scoring service using Databricks MLflow.
Outcome:
- Fraudulent patterns were detected with high accuracy.
- Model deployment was streamlined, enabling real-time predictions.
3. Real-Time Alerts and Dashboards
- Problem: Fraudulent transactions needed to trigger immediate alerts.
- Solution:
- Detected fraudulent transactions were sent to Azure Logic Apps, which triggered notifications to the fraud detection team via email and SMS.
- Transaction and fraud metrics were visualized in near-real-time using Azure Power BI dashboards integrated with the Delta Lake.
Outcome:
- Reduced response time for fraud detection teams.
- Clear visibility into transaction trends and fraud metrics.
4. Scalable Data Storage with Delta Lake
- Problem: Large volumes of historical and real-time data needed efficient storage and querying.
- Solution:
- Delta Lake was used to store transaction data, enabling ACID compliance and versioning.
- Batch and real-time data processing were unified, ensuring consistent data quality.
Outcome:
- Faster queries and reliable data pipelines.
- Simplified data engineering workflows.
Implementation Process
1. Architecture Design
- Designed a solution architecture integrating Azure Event Hubs, Azure Databricks, Delta Lake, and Azure Logic Apps.
- Ensured scalability and fault tolerance at every stage of the pipeline.
2. Data Pipeline Development
- Developed data ingestion pipelines in Databricks using PySpark.
- Implemented data cleaning and transformation processes to standardize incoming data.
3. Machine Learning Model Development
- Explored and preprocessed historical data to identify features for fraud detection.
- Built and tuned the Random Forest model using Databricks MLlib.
- Automated model retraining and deployment using MLflow.
4. Dashboard Integration
- Connected Delta Lake with Power BI to create live dashboards for transaction monitoring and fraud analytics.
Results Achieved
Real-Time Fraud Detection
- Fraudulent transactions were identified within seconds, reducing financial losses.
Improved Accuracy
- Machine learning algorithms achieved a 98% accuracy rate in identifying fraudulent patterns.
Scalability and Performance
- Azure Databricks scaled effortlessly to process over 10 million transactions daily.
Actionable Insights
- Power BI dashboards provided actionable insights into transaction trends and fraud metrics.
Cost Efficiency
- Migrating to Azure Databricks reduced infrastructure costs by 40%.
Architecture Overview
The solution architecture includes:
- Azure Event Hubs for real-time data ingestion.
- Azure Databricks for processing, machine learning, and data storage.
- Delta Lake for unified batch and streaming storage.
- Azure Logic Apps for alerting.
- Azure Power BI for visualization.
Categories
Recent Posts
Start Your Data Journey Today With MSAInfotech
Take the first step towards data-led growth by partnering with MSA Infotech. Whether you seek tailored solutions or expert consultation, we are here to help you harness the power of data for your business. Contact us today and let’s embark on this transformative data adventure together. Get a free consultation today!

We utilize data to transform ourselves, our clients, and the world.
Partnership with leading data platforms and certified talents


 +1 (339) 699-3312
+1 (339) 699-3312 +91 9033291637
+91 9033291637